


… und was ist heute möglich?
Viele Menschen sind begierig darauf, etwas über die Zukunft zu erfahren. Es spielt dabei keine Rolle, ob eine Zigeunerin auf dem Jahrmarkt etwas über die persönliche Zukunft erzählt oder ein mathematisches Modell über die weitere Entwicklung eines Unternehmens. Das Wort „Vorhersage“ hat eine geheimnisvolle Bedeutung und maschinelles Lernen ist in aller Munde. Aber wie funktioniert das eigentlich genau?
Als in den 50iger Jahren zum ersten Mal der Begriff des maschinellen Lernens aufgetaucht ist, konnte sich niemand vorstellen, dass es 50 Jahre später ein heißer Trend für High-Tech-Firmen werden würde. Aber heutzutage ist es keine Übertreibung, wenn wir sagen, dass ML (Machine Learning) zu den Top-Fähigkeiten gehört, nach denen Unternehmen suchen, denn Einsatzgebiete und Möglichkeiten sind nahezu grenzenlos. Aber was ist ML eigentlich?
Begriffsdefinition
Maschinelles Lernen ist ein Teilgebiet von künstlicher Intelligenz (KI), die es Softwareanwendungen ermöglicht, Ergebnisse genauer vorherzusagen, ohne dass sie explizit dafür programmiert werden müssen. Die praktische Umsetzung geschieht mittels Algorithmen. Diese verwenden historische Daten als Input, um neue Output-Werte vorherzusagen. Das Wort Vorhersage wird nun im Rahmen von zukünftigen Entwicklungen für Unternehmen immer wichtiger.
Was macht nun ML?
Machine Learning versucht aus Daten der Vergangenheit zu lernen und ungesehene Daten für die Zukunft vorherzusagen. Es versucht also Muster und Gesetzmäßigkeiten in den Lerndaten zu erkennen und unbekannte Daten danach zu beurteilen.
Wie funktioniert das im Detail?
Wir haben immer einen Datensatz, den wir mit ML-Modellen anwenden wollen, um ein Modell darauf zu trainieren und für die Zukunft zu verwenden. Hier gilt natürlich, je mehr Daten vorliegen, umso präziser wird die Vorhersage.
Hier ein Beispiel zur Verdeutlichung:
In der nachfolgenden Tabelle sehen wir unterschiedliche Merkmale einer Immobilie. Wir sehen einen Ausschnitt der Datensätze. Jede Zeile heißt „Example“ und jede Spalte „Feature“. Der vorherzusagende Wert wird als „Label“ bezeichnet. Hier wollen wir den Hauspreis auf der Grundlage einiger Attribute (features) wie der Anzahl der Schlafzimmer vorhersagen. Der Hauspreis ist hier unser „Label“.
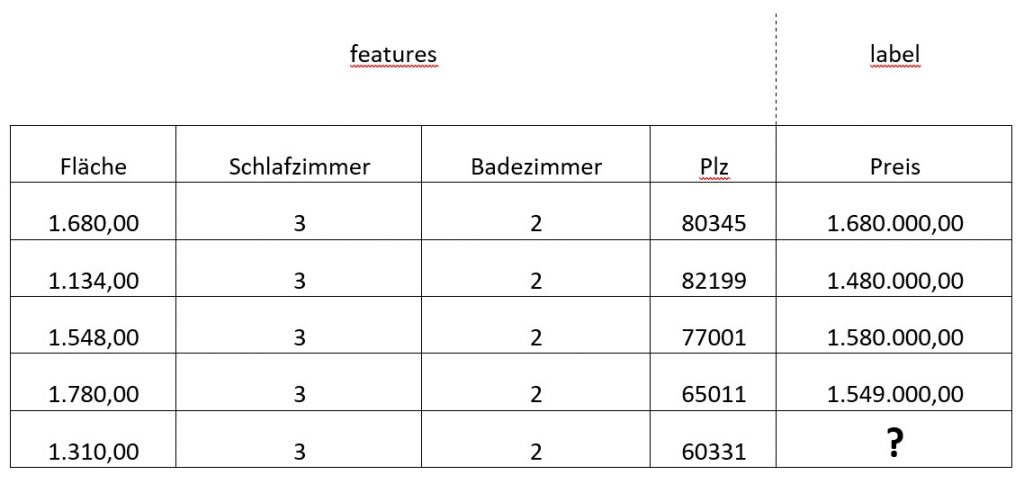
Unterschiedliche Vorhersageprobleme
Man unterscheidet zwei Teilgebiete von ML:
- Überwachtes Lernen
- Unüberwachtes Lernen
Beim „überwachten Lernen“gibt es einen Wert, den wir vorhersagen werden. Das spezifische Merkmal, das wir vorhersagen wollen, wird auch Klasse oder Ziel genannt. Basierend auf der Art dieses Wertes haben wir zwei verschiedene Arten von überwachtem Lernen. Wenn der Wert, den wir vorhersagen wollen, diskret ist, ist die Vorgehensweise die sogenannte Klassifikation. Unter Klassifikation versteht man den Prozess des Findens oder Entdeckens eines Modells oder einer Funktion. Wenn dieser Wert kontinuierlich ist, ist die Vorgehensweise Regression. Unter Regression versteht man den Prozess des Findens eines Modells oder einer Funktion zur Unterscheidung der Daten in kontinuierliche reale Werte anstelle der Verwendung von Klassen oder diskreten Werten.
Sie kann auch die Verteilungsbewegung in Abhängigkeit von den historischen Daten identifizieren. Da ein Regressionsvorhersagemodell eine Menge vorhersagt, muss daher die Fähigkeit des Modells als Fehler in diesen Vorhersagen angegeben werden.
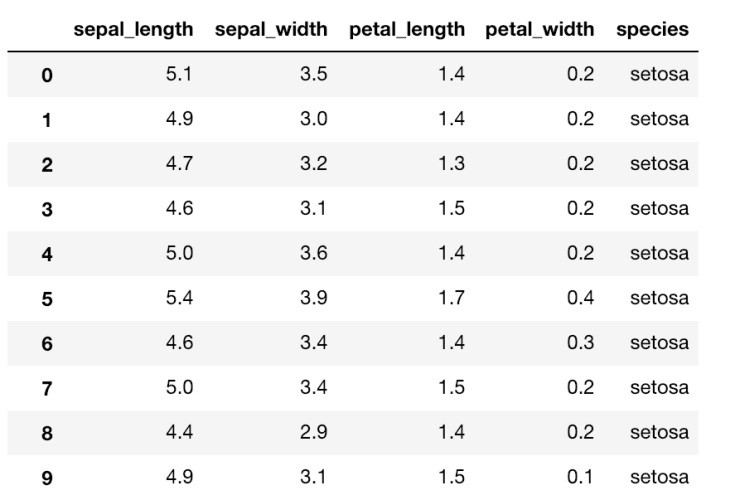
In der nachfolgenden Abbildung sehen Sie Beispiele für Merkmale und Label für Klassifikationen und Regressionsprobleme.
Klassifikation (label species)
Regression (label profit)

Abgesehen vom „überwachten Lernen“ haben wir„unüberwachtes Lernen“, für das kein Label verfügbar ist.
Bei „unüberwachten Lernen“ suchen wir einfach nach verschiedenen Clustern in unseren Daten, die sich irgendwie ähnlich verhalten. Wir sagen hier nichts voraus. Das ML-Modell bei dieser Art von Problemen lernt einfach eine gewisse Trennung zwischen den Gruppen in den Daten und ordnet dann zukünftige Daten einem der entdeckten Cluster zu.
Theorie & Praxis
Es ist darüber hinaus wichtig zu wissen, dass es einen großen Unterschied zwischen ML in der Theorie und ML in der Praxis (Produktion) gibt. Heutzutage wird man kaum eine Firma finden, die ML nicht nutzen möchte, aber in den letzten 5 Jahren habe ich viele ML-Projekte gesehen, die nicht die gewünschten Ergebnisse geliefert haben.
Das erste, was wir beim Start eines ML-Projekts daher berücksichtigen müssen, ist realistisch zu sein. ML kann sehr wertvolle Ergebnisse liefern, aber es müssen bestimmte Voraussetzungen erfüllt sein, um dies zu erreichen. Wenn auch nur eine dieser Voraussetzungen fehlt, wird das Ergebnis nicht sehr aussagekräftig sein. Ich habe selbst in großen Unternehmen viele übertriebene Erwartungen an ML gesehen, die verhinderten, dass gute und sinnvolle Ergebnisse erzielt wurden.
Daher mein Tipp an dieser Stelle: Gehen Sie realistisch an ML heran. Es gibt so zum Beispiel eine umgekehrte Korrelation zwischen der Leistung des ML-Modells und den Erwartungen des Unternehmens. Je mehr Zeit verstreicht, desto stärker wird diese Korrelation positiv, und umso wertvoller werden die Ergebnisse für Sie sein.
Ausblick
Datenqualität, Datengröße und… dies sind weitere typische Herausforderungen beim Machine Learning, über die ich in Teil 2 dieser Reihe sprechen werde, der im nächsten its-people Magazin erscheinen wird.
Teil 2: https://its-people.de/wie-man-probleme-des-maschinellen-lernens-angeht
Seien Sie gespannt!



