

Es ist erstaunlich, dass das Thema Kundendaten-Qualität immer noch zu einem der Top-Themen in der IT zählt. Dieses zieht sich seit nunmehr über 25 Jahren durch die Systeme und ist noch lange nicht zu einem befriedigenden Abschluss gelangt. Daher lohnt es sich auch jetzt, in Zeiten von Big Data und Advanced Analytics, wieder diese Problematik zu beleuchten.
Big Data lebt, zumindest bei nicht technischen Daten (Internet of Things), von dem Versprechen der Individualisierung von Massendaten. Das bedeutet, im Gegensatz zu den klassischen Data Warehouse Ansätzen, die mit Clustering und Segmentierung Gruppen von gleich zu behandelnden Kunden zu identifizieren versucht, soll mit den ungleich größeren Datenmengen im Big Data, der Kunde als einzelnes Individuum erfasst, vermessen und marketing-technisch bearbeitet werden. Das Ziel ist es für ein Unternehmen, egal ob Onlineshop, Versicherung oder Autohersteller, dass maßgeschneiderte Angebot für einen dedizierten Kunden zu finden. Dies scheitert allerdings grandios, wenn man die ureigensten Kundeninformationen wie zum Beispiel Name, Geschlecht und Adresse datentechnisch dabei nicht im Griff hat!
Die Ursachen aller Kundendaten-Qualitätsprobleme liegen in der Quelle: der Datenerfassung.
Hierbei kommt es klassischerweise zu folgenden Fehlern:
-
Fehlende Angaben:
Die Kundeninformationen werden nicht vollständig erfasst. Das ist meist darin begründet, dass die Felder der Eingabemasken, in denen die Kundeninformationen erstmalig erfasst werden, nicht genügend auf Vollständigkeit und Korrektheit überprüft werden
-
Abweichende Schreibweisen:

Der Klassiker ist hier der Umlaut, München und Muenchen ist zwar fachlich, aber nicht technisch gleich
-
Widersprüchliche Angaben:
Die Postleitzahl passt nicht zur Stadt oder die Hausnummer existiert in der Straße nicht. Alles Fehler, die auf ungenügende Prüfungen bei der Eingabe deuten
-
Dubletten:
Diese können durch obigen Fehler entstehen, oder aber durch die Erfassung des Kunden in unterschiedlichen Systemen mit unterschiedlichen Eingaben. Die Erfassungssysteme sind hierbei nicht ausreichend integriert
-
(Familien)-Cluster:
Zwei oder mehr Personen werden nicht als zu einem Haushalt gehörend identifiziert. Oder der umgekehrte Fall: zwei namensähnliche Bewohner einer Adresse werden fälschlicherweise zu einem Haushalt gezählt
-
Veraltete Daten:
Umzüge, Namensänderungen usw. sind dem Unternehmen nicht bekannt und führen zu Dubletten oder ungültigen Daten
Die gravierendsten Folgen von derartigen Qualitätsproblemen sind:
- Rechnungen können nicht zugestellt werden
- Werbemittel werden unnötig mehrfach versandt
- Der Kunde fühlt sich nicht adäquat angesprochen
Die Lösung all dieser Probleme liegt idealerweise dort, wo sie auch entstehen: in den Systemen, die den Kundenerstkontakt managen. Leider kann aber diese Forderung meist nicht umgesetzt werden. Zum einen treten die Probleme in der Regel nicht in den Systemen selbst auf, sondern erst in den nachgelagerten Verarbeitungsprozessen oder den BI-Systemen. Hierbei spielt die Frage der Zuständigkeit eine große Rolle.
Zum anderen gibt es technische Restriktionen, die es nicht erlauben, dass die Erfassungssysteme ausreichend miteinander oder auch mit einem klärenden Drittsystem kommunizieren. Den für BI-verantwortlichen Abteilungen bleibt meist nichts anderes übrig, als diese Probleme im Rahmen ihrer ETL-Aktivitäten zu lösen. Leider wird hierbei viel zu wenig auf standardisierte Produkte gesetzt, die zugegebenermaßen preislich recht hoch angesiedelt sind. Viel zu häufig wird versucht, mit Individuallösungen zu arbeiten, die meist daran kranken, dass der zum Vergleich herangezogene Referenz-Datenbestand selbst nicht den Umfang und die Qualität hat, die vonnöten ist. Auch die Algorithmen zum mustertoleranten Vergleich sind bei Individual-Entwicklungen meist weniger ausgeklügelt, als bei Spezial-Produkten.
Eine optimale Kundendaten-Bereinigung besteht aus mindestens zwei Schritten:
- Adress-Verifikation
Hierbei werden postalische Adressen auf Vollständigkeit, korrekte Schreibweise, Gültigkeit und Akronyme kontrolliert. Fehlende Angaben werden, soweit möglich ergänzt. Wichtig ist hier die Qualität des Referenzdatenbestands.
Beispiel:

- Namens-/Adress-Vergleich
Beim Namens- und Adressvergleich kann in der Regel nicht auf einen Referenz-Datenbestand zurückgegriffen werden, da es kein Namensverzeichnis der aktuellen Weltbevölkerung gibt und auch kein öffentlich zugängliches Verzeichnis aller Namen in Deutschland. Hier wird von den Werkzeugen her anders vorgegangen. Der Namen und die Namensbestandteile werden in phonetische Strukturen zerlegt. Diese werden dann miteinander verglichen und eine Trefferwahrscheinlichkeit ermittelt. Diese gibt an, mit welcher Wahrscheinlichkeit zwei angegebene Namen in unterschiedlicher Schreibweise, zusammen mit ihrer Adresse identisch sind. Die Genauigkeit der Aussage steigt, je mehr Attribute über den betroffenen Kunden bekannt sind. Es wird dann ein Schwellwert definiert (z.B. 95%), ab dessen die Gleichheit angenommen wird.
Der Namens-/Adress-Vergleich wird nach der Adress-Verifikation durchgeführt, so dass auf standardisierte Adressen zurückgegriffen werden kann.
Beispiel:
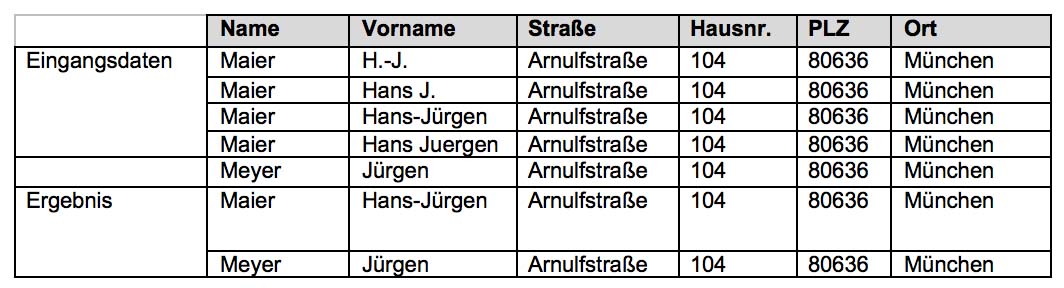
Im Rahmen eines Datenbewirtschaftungs-Prozesses müssen alle eingehenden Adress- und Kunden-Daten durch die entsprechende Spezialsoftware geschleust werden. Die Ergebnisse können dann im weiteren Verlauf als Basis verwendet werden.
Im Idealfall werden die Ergebnisse der Kundendaten-Bereinigung an die Quellsysteme zurückgemeldet, so dass auch hier eine Korrektur erfolgen kann.
Zusammengefasst: Eine funktionierende Kundendaten-Bereinigung muss Bestandteil einer funktionierenden BI-Lösung sein. Die Vorstellung nur valide und qualitätsgesicherte Kundendaten aus den Quellsystemen zu bekommen, ist ansonsten in den wenigsten Fällen zu realisieren.



